When to use 3D Die-Stacked Memory for Bandwidth-Constrained Big Data Workloads
Local Download arXiv Link Presentation (PDF) Interactive Data
Paper overview
3D die-stacking is an exciting emerging technology. It promises extremely high bandwidth interconnects for relatively power (at least when compared to current memory technology). Some of my previous work has looked at how this increased bandwidth can significantly improve performance. This is especially true for bandwidth-constrained workloads, like database scan. However, my previous work has totally ignored the practicality of building these systems. In this post (and in the paper I am presenting at BPOE), I’d like to dig into whether, and/or when, 3D die-stacking is really appropriate, with a focus on big-data workloads.
While 3D die-stacking promises higher memory bandwidth, it comes at the cost of tiny capacities. Today, each stack of DRAM has 2–4 GB of capacity. Looking forward this should increase to 8–16 GB in the next few years due to increased DRAM densities and more chips per stack. Compare this to commodity DIMMs for which you can easily buy a single DIMM with 32 GB, and companies have announced DIMMs up to 128 GB.
One of the first observations I made when I began looking at 3D stacking is that current systems are incredibly unbalanced for high-bandwidth workloads like scan. There is currently a big push for in-memory databases, OEMs are designing systems for this workload. For instance, you can buy a system from Dell (the PowerEdge R930) with 3 TB of DRAM! Granted, it’s likely to cost between $50,000 and $100,000, but Dell is happy to sell it to you. Oracle and IBM are also selling similar systems with even more DRAM per socket. So, looking at this system I asked, “What’s the most complex query I can make if I only have 10ms to complete it?” I chose 10 ms as a proxy for a very aggressive SLA (service level agreement). The visualization below will give you an idea of what this looks like for the Dell system described above.
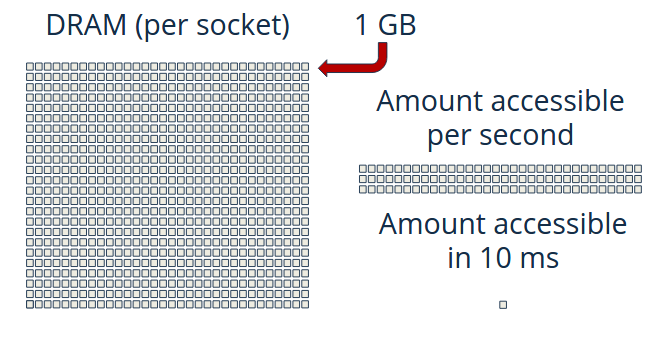
In this system, you can only access 0.13% of the total data in 10ms! In fact, it would take over 7 seconds to read all of the data. (You can take the bandwidth (408 GB/s) and multiply by the time (10 ms) to find how much data you can access in 10 ms (4 GB). Then, compare this to the total memory ( 3 TB) to get 0.13% of memory capacity accessible in 10 ms.)
Let’s compare this to the die-stacked system pictured below.


For the die-stacked system, you can access 32% of the data in 10 ms. This is over 200 times more than in the traditional system.
So, it seems that the die-stacked system is way better for bandwidth constrained workloads. And this is the same conclusion I had in previous work. However, this ignores the fact that the capacity of the die-stacked system is more than an order of magnitude smaller than conventional systems. Because of this small capacity, you would need many more die-stacked systems to store the same amount of data as a single traditional system. For instance, if you have a 16 TB workload, you would need only 5–6 of the Dell servers, but you would need over 2000 die-stacked systems.
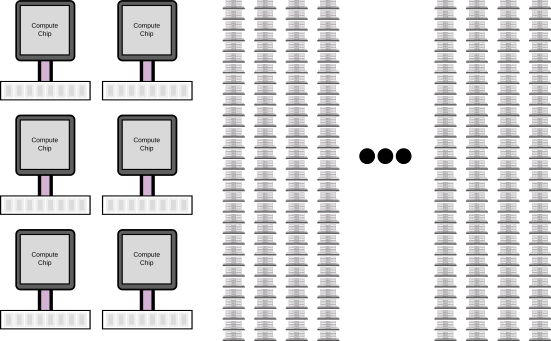
The systems required for a 16 TB workload. While you only need 6 traditional systems, you need over 2000 of the die-stacked systems (which don’t even fit in the image)!
Having so many die-stacked systems greatly increases the power required to run the workload. And this is the fundamental trade off that we investigated in our BPOE paper. In a sentence, we found that if you require very high performance (like a 10ms SLA), the die-stacked system is the most reasonable system to build. However, if you have a less strict SLA (100ms or more) or if you have strict power constraints, then the traditional system is the best.
To reach these conclusions, we developed a simple back-of-the-envelope style analytical model for the power, performance, and capacity of these systems. If you’re interested in more details, you can find the entire model here: 3D Bandwidth Model. You can download the IPython (Jupyter) Notebook from that page and run the model interactively on your local computer. Of course, you can also read the paper. You can download it from here: Paper link.
@inproceedings{adbm:Lowe-Power:2016,
author = {Jason Lowe{-}Power and Mark D. Hill and David A. Wood},
title = {When to use 3D Die-Stacked Memory for Bandwidth-Constrained Big Data Workloads},
booktitle = {The Seventh Workshop on Big Data Benchmarks, Performance Optimization, and Emerging Hardware (BPOE 7) at ASPLOS},
year = {2016},
}
@article{adbm-arxiv:Lowe-Power:2016,
author = {Jason Lowe{-}Power and Mark D. Hill and David A. Wood},
title = {When to use 3D Die-Stacked Memory for Bandwidth-Constrained Big Data Workloads},
journal = {CoRR},
volume = {abs/1608.07485},
year = {2016},
url = {http://arxiv.org/abs/1608.07485},
archivePrefix = {arXiv},
eprint = {1608.07485},
}
Comments