Performance Analysis of Scientific Computing Workloads on General Purpose TEEs
IEEEXplore Local Paper Download Extended ArXiV version Presentation Download Presentation Video Source Code
HPC TEEs
Scientific computing sometimes involves computation on sensitive data. Depending on the data and the execution environment, the HPC (high-performance computing) user or data provider may require confidentiality and/or integrity guarantees. The table below shows some examples of sensitive data which providers may want to share with data scientists.
| Domain | Data provider | Data types | Applications |
|---|---|---|---|
| Health care | Hospital or VA | Health records, medical images, gene sequences | Machine learning models |
| Transportation | Public transportation, delivery/logistics firms | driving routes | graph analysis, optimization |
| Energy | Utility company | Home & building energy usage | Real-time demand/response prediction |
One possible architecture to enable HPC on sensitive data is to leverage trusted execution environments. Although these were originally designed for a narrow set of workloads, new hardware-accelerated TEEs like AMD’s SEV and Intel’s SGX may provide the perfomance and programmability required for HPC.
Thus, in this paper we study a diverse set of workloads on AMD SEV and Intel SGX.
We make the following three findings:
SEV may be suitable for HPC with careful memory management
With a NUMA-aware data placement policy, we find that the slowdown when running HPC applications with SEV is managable (1-1.5x slowdown). However, without careful data placement, the slowdown can be significant (1-3.4x) compared to running the application without SEV enabled.
The graphs below explain why SEV doesn’t work well with the default NUMA placement. The first image is the memory allocated over time when SEV is enabled. This bar shows that all of the memory is allocated on one NUMA node reducing the peak memory bandwidth and increasing the memory latency for the application. Compare this with the next figure which shows the memory allocated over time when we disable SEV. The data is spread nearly evenly across all of the NUMA nodes increasing the memory bandwidth and improving the performance.
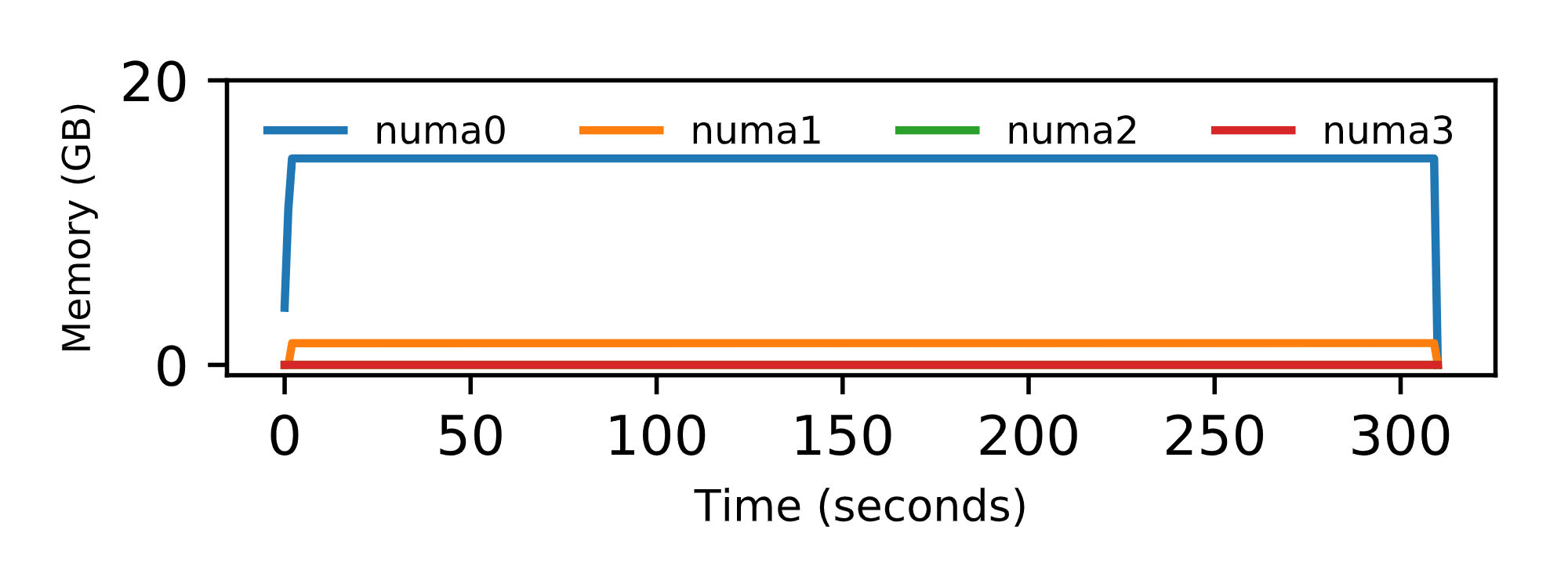
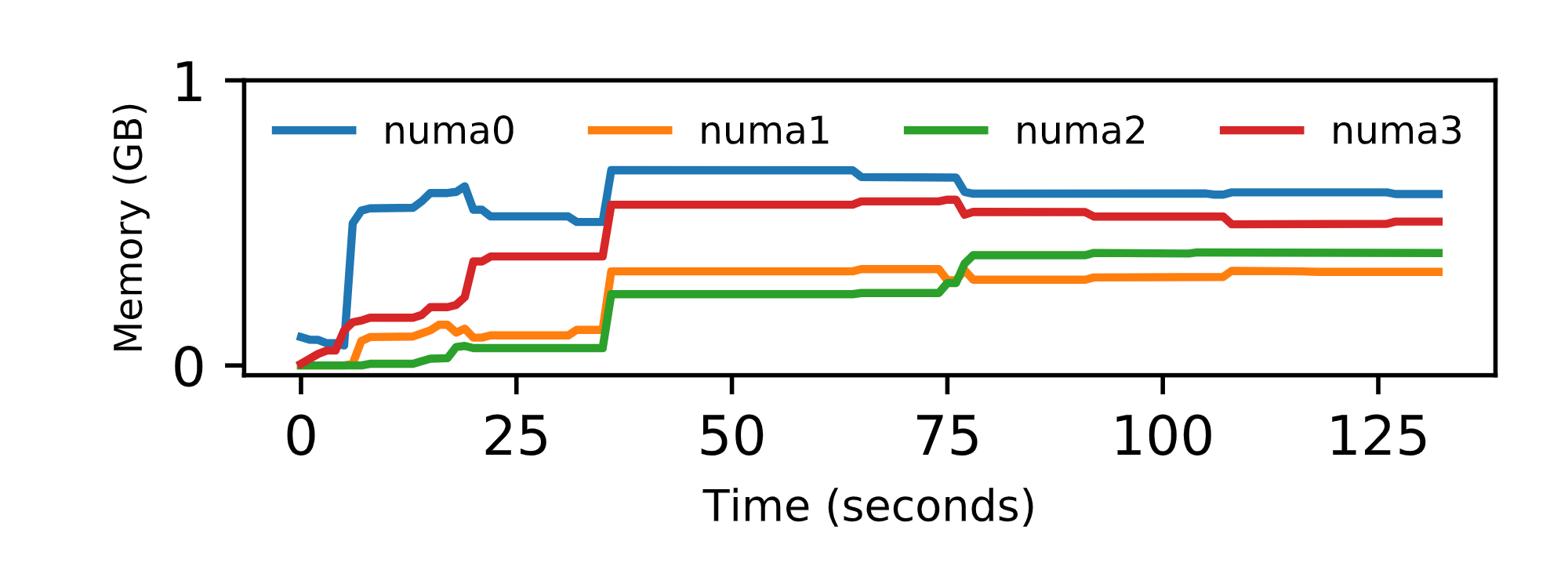
To solve this problem, you can either carefully configure your virtual machine with the same NUMA arrangement as the host platform, or you can force the system to interleave the memory allocation when spawning the virtual machine.
Virtualization required by SEV hurts performance
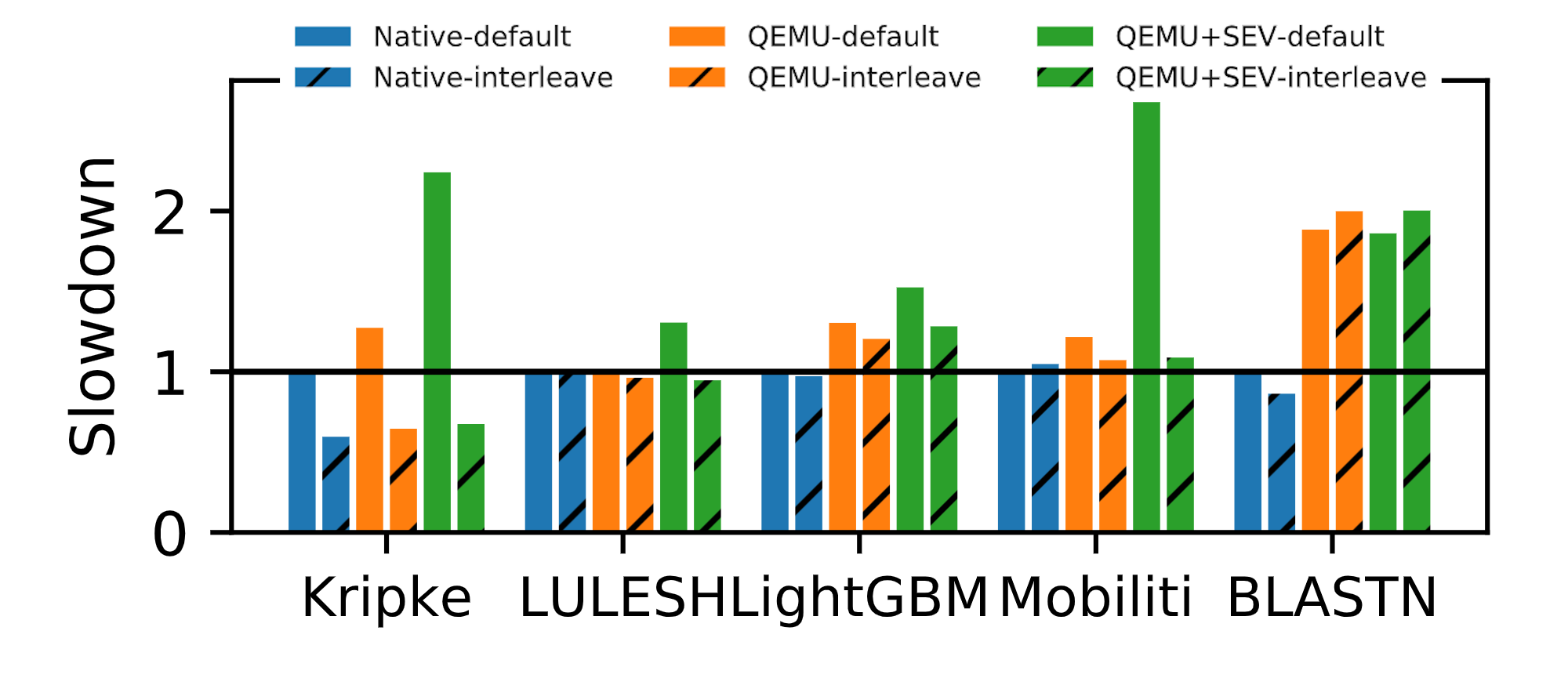
To use AMD’s SEV, you must run your workload inside a virtual machine. Virtualization is well known to cause performance problems for memory-intensive workloads. However, we also found that some I/O intensive workloads, which are not uncommon for big data applications in HPC, suffer from virtualization overheads as well. That said, most workloads perform about the same with SEV and when they are executed natively.
This figure shows the slowdown relative to native exeution for some “real world” HPC workloads. The key bar is the one on the right of each set (green, hatched) which shows the performance of SEV with NUMA interleaving enabled.
SGX is inappropriate for HPC applications
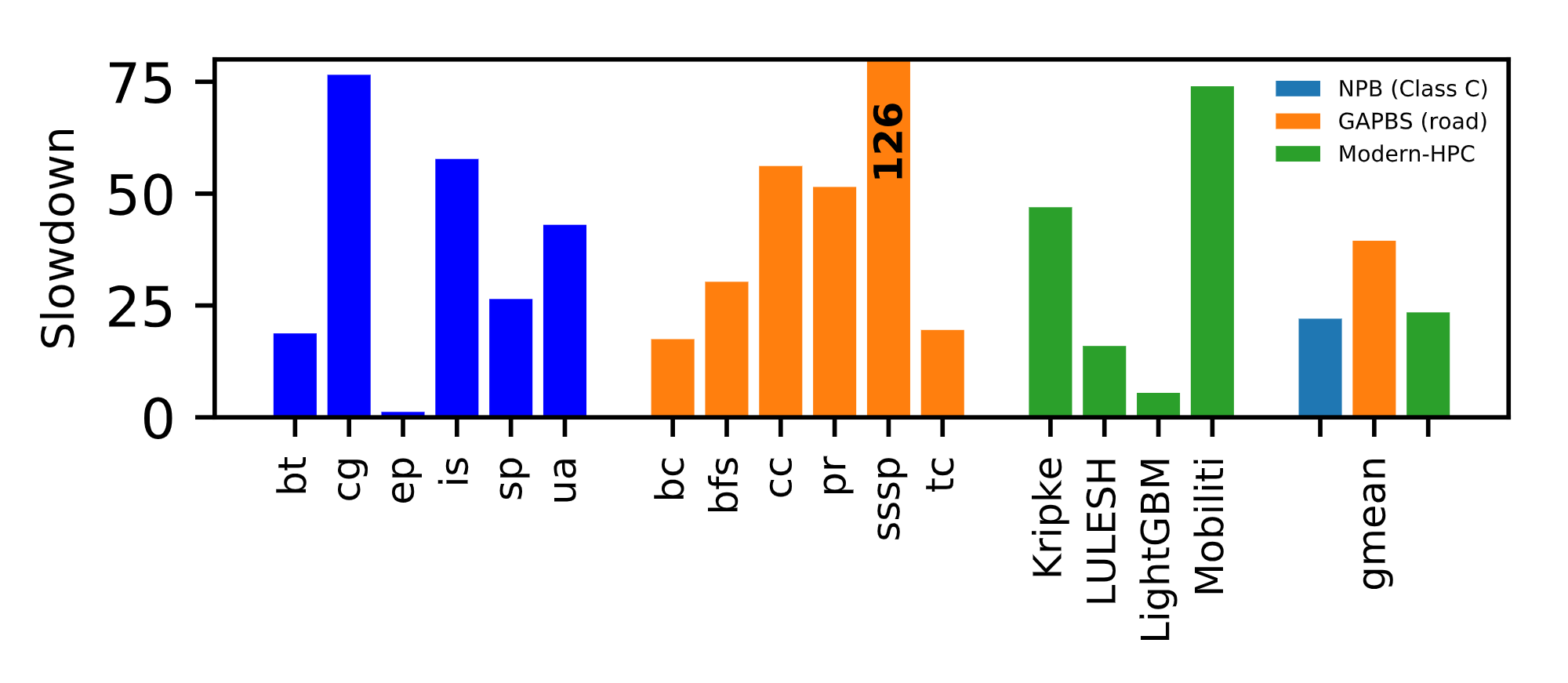
Finally, we also evaluated Intel’s SGX and found that it was not appropriate for running HPC applications. SGX was designed for applications which can be easily partitioned into “secure” and “insecure” and that don’t execute much computation in the “secure” portion.
Thus, we found that SGX has the following problems.
- It was difficult to program. Running unmodified applications was very difficult, and, in some cases, impossible.
- SGX is limited in the amount of memory a program can access (~100 MB on our system and ~200MB on more recent designs). This is a poor fit for HPC applications which may require 100s GB of working memory.
- System calls and multi-threading perform poorly on SGX.
Overall, we found extreme performance penalties when running workloads on SGX as shown below.
Related posts
You can find more information about how we ran our experiments in this blog post on Setting up Trusted HPC System in the Cloud.
Acknowledgements
This work was performed in collaboration with Lawrence Berkeley National Labs.
Citation
Ayaz Akram, Anna Giannakou, Venkatesh Akella, Jason Lowe-Power and Sean Peisert, “Performance Analysis of Scientific Computing Workloads on General Purpose TEEs,” 2021 IEEE International Parallel and Distributed Processing Symposium (IPDPS), 2021, pp. 1066-1076, doi: 10.1109/IPDPS49936.2021.00115.
@INPROCEEDINGS{akram2021hpctee,
author={Akram, Ayaz and Giannakou, Anna and Akella, Venkatesh and Lowe-Power, Jason and Peisert, Sean},
booktitle={2021 IEEE International Parallel and Distributed Processing Symposium (IPDPS)},
title={Performance Analysis of Scientific Computing Workloads on General Purpose TEEs},
year={2021},
pages={1066-1076},
doi={10.1109/IPDPS49936.2021.00115}
}
Comments