AutoTM: Automatic Tensor Movement in Heterogeneous Memory Systems using Integer Linear Programming
Paper on ACM DL Local Paper Download CK Presentation Download Presentation Video Source Code
AutoTM
Machine learning model size is growing at an enormous pace. Especially when training with large batch sizes (e.g., 1024-2048), some workloads require over 1 TB of memory capacity. In these big memory systems, the cost of DRAM dominates the system cost.
At the same time, new memory technologies promise to reduce to cost of main memory (RAM) and provide nearly the same performance as DRAM. Recently, Intel released Intel Optane DC which packages 3D-XPoint memory technology in a DIMM compatible with the DDR interface. In theory, this new technology could lower the cost of training these very large deep neural networks. In AutoTM, we investigate the performance impact of replacing a subset of system RAM with Intel’s 3D-XPoint memory and develop novel algorithms to reduce the performance penalty.
3D-XPoint and deep learning
3D-XPoint memory (marketed as Intel Optane DC) is a byte addressable memory technology with latency slightly higher than DRAM. Izraelevitz et al. provide a detailed analysis of the performance of current 3D-XPoint devices.
Current Cascade Lake systems provide two different ways to access the heterogeneous memory system: “2LM” or two level memory which uses the DRAM as a hardware managed cache of the backing 3D-XPoint memory and “1LM” or one level memory which splits the DRAM and 3D-XPoint into two separate memory spaces for the programmer to manage.
As an initial test, we analyzed the performance of four different image recognition deep learning models: VGG, Inception, ResNet200, and DenseNet. We configured the training of each of these models to use “a lot” of memory (between 300GB and 1TB), and ran a training iteration on two different systems: a system with only DRAM (the model must be smaller than the 192GB DRAM in our system) and a system with only 3D-XPoint.
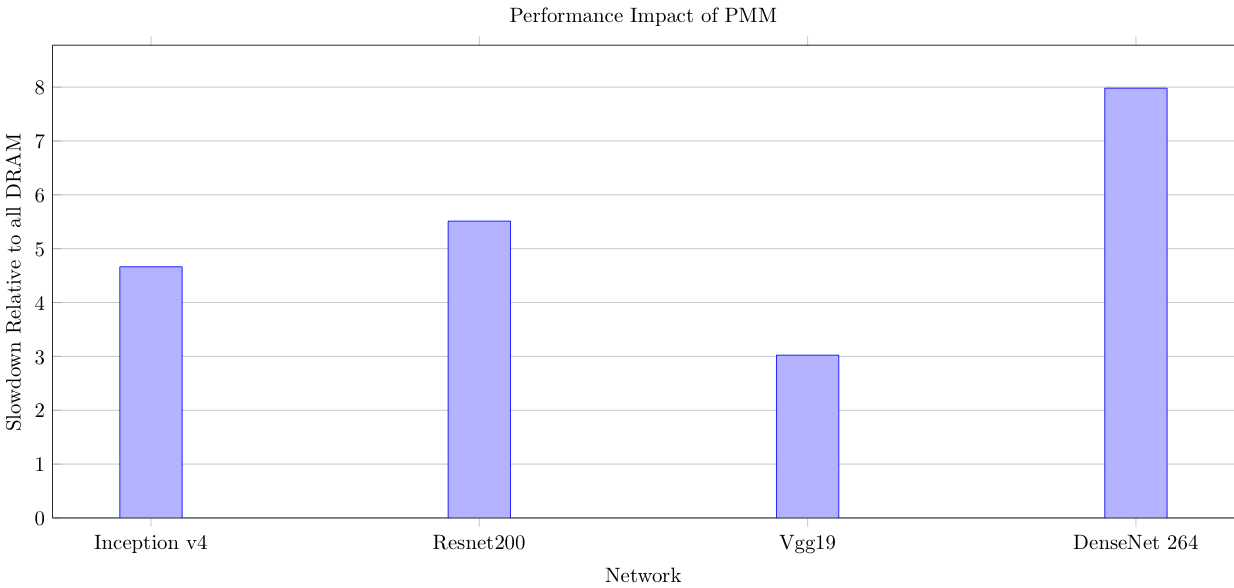
This figure shows that if we naively replace DRAM with persistent memory, there is a huge performance reduction. It is unlikely that users will accept taking a 3-8x performance hit to save a little money on their RAM.
We also evaluated the performance of these workloads using the DRAM as a cache of 3D-XPoint memory (2LM mode), and we found that the cache performance was poor. Below, we show the performance of the DRAM cache compared to AutoTM. More details of the DRAM cache mode performance can be found in the full AutoTM paper, and we are currently working to flesh out the reasons why AutoTM works better than the DRAM cache.
Key insight: An optimization problem
Our key insight in this work is that we can formulate the data movement problem as an integer linear program.
Many machine learning frameworks express their computation as a graph of compute kernels connected by tensors of data. Specifically, we use Intel nGraph which assumes all tensors are immutable and kernels are idempotent. With this static compute graph, we can ask the question: for every kernel, what is the performance if the data is in DRAM or in 3D-XPoint memory?
We also extend nGraph with a new “move” kernel which moves a tensor from DRAM to 3D-XPoint or vice versa. We similarly profile these move kernels to record the amount of time it takes to transfer each tensor.
After gathering all of the profiling data, we can ask an optimization engine: “find me the memory locations of tensors and tensor move operations such that 1) we get the right answer and 2) we minimize the total time taken.” Thus, we have automatic tensor movement: AutoTM!
There are many more details of our ILP formulation in the full paper.
Results
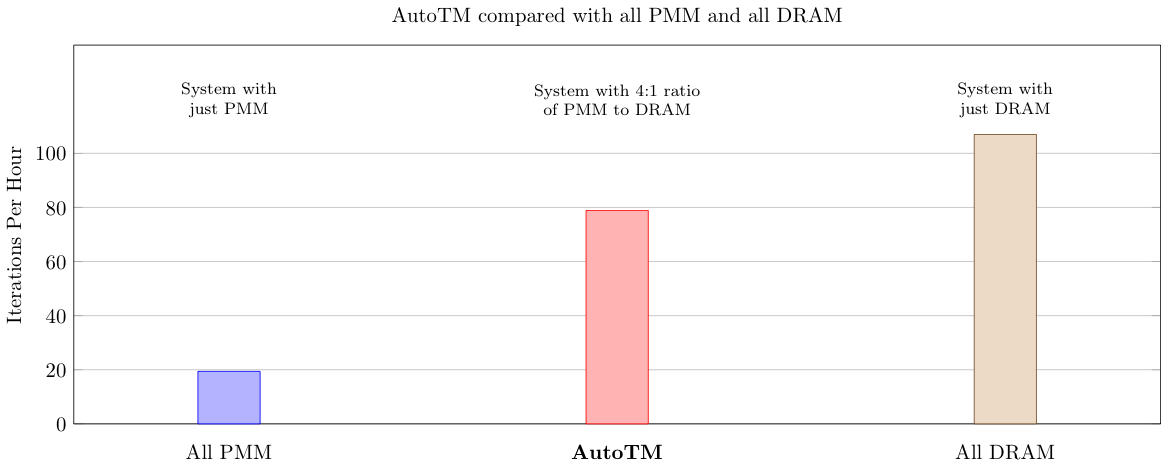
This figure shows the performance of AutoTM compared to only DRAM (top line) and 3D-XPoint. This shows that AutoTM give much better performance that pure 3D-XPoint and acceptable performance relative to pure DRAM.
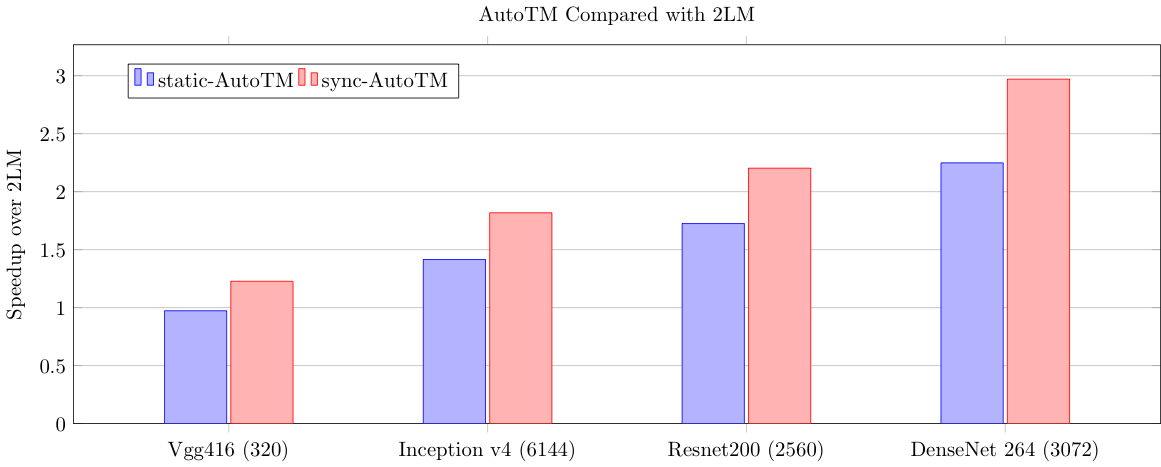
Above, we show the performance of AutoTM compared to 2LM. In this test, we use very large training workloads with working sets over 650 GB. This shows that AutoTM outperforms even a hardware-based cache!
We are currently digging deeper into this result to understand why AutoTM performs so much better than the hardware-based caching schemes. We believe that if we can better understand where AutoTM’s performance benefits come from we may be able to further generalize our technique to more workloads (e.g., HPC and graph workloads).
Finally, we analyzed the cost of systems with 3D-XPoint compared to DRAM. We used prices found on Lenovo’s website accessed in August 2019. An important caveat is that the price of 3D-XPoint is a business, not a technological decision. We do not know the fundamental costs associated with 3D-XPoint as they have not been made available by Intel.
Using these prices, we found that if we only consider the cost of RAM, 3D-XPoint may be able to save you a little money (not a blockbuster result!). After analyzing many different DRAM to 3D-XPoint ratios, we found that at a ratio of 1:8 (i.e., 8x more 3D-XPoint) you can save about 50% of your DRAM cost while AutoTM ensures only a 30%-60% slowdown depending on the workload. It’s worth it for some workloads and not worth it for others.
However, real systems have more components than just DRAM. When you include the cost of the CPU, system components (motherboard, case, powersupply, etc.), and energy over the lifetime of the system (i.e., use the total cost of ownership), the cost reduction due to 3D-XPoint disappears. So, we’re asking the question: “What is the business argument for including 3D-XPoint in your system?”
Other things in the paper
We cover a lot more ground in the paper. We provide many more results for different workloads and sizes, we delve deeply into how we formulate our ILP problem and how this is integrated with nGraph, and we give some intuition on what the ILP finds to be the best solution (i.e., when and which tensors to move).
Additionally, we extend AutoTM to use asynchronous movement (i.e., overlap movement with compute). We thought this would increase the performance by overlapping data movement with computation, but we found that it actually hurt performance due to interference at the memory controller! However, we tried the asynchronous idea on GPUs by implementing AutoTM to move data between CPU and GPU DRAM instead of DRAM and 3D-XPoint memory and found that our intuition was correct and asyncronous movement can improve performance. By extending AutoTM to CPU-GPU data movement we futher show the generality of applying optimization to the problem of data movement in static compute graph computations like deep learning training.
Full conference video
Acknowledgements
This work in sponsored by Intel.
Mark Hildebrand, Jawad Khan, Sanjeev Trika, Jason Lowe-Power, and Venkatesh Akella. 2020. AutoTM: Automatic Tensor Movement in Heterogeneous Memory Systems using Integer Linear Programming. Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems. Association for Computing Machinery, New York, NY, USA, 875–890. DOI:https://doi.org/10.1145/3373376.3378465
@inproceedings{10.1145/3373376.3378465,
author = {Hildebrand, Mark and Khan, Jawad and Trika, Sanjeev and Lowe-Power, Jason and Akella, Venkatesh},
title = {AutoTM: Automatic Tensor Movement in Heterogeneous Memory Systems Using Integer Linear Programming},
year = {2020},
isbn = {9781450371025},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3373376.3378465},
booktitle = {Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems},
pages = {875–890},
numpages = {16}
}
Comments