A Case Against Hardware Managed DRAM Caches for NVRAM based Systems
Paper on IEEE Xplore Local Paper Download Presentation Download Presentation Video
DRAM Caches don’t work well (for large workloads)
Non-volatile memory (NVRAM) based on phase-change memory (such as Optane DC Persistent Memory Module) is making its way into Intel servers to address the needs of emerging applications that have a huge memory footprint. You can now buy systems with up to 6TB main memory, and this capacity is expected to grow with the next generation of devices. However, NVRAM is slower than DRAM (2-5x longer latency for reads and even worse for writes). Thus, you may be thinking “why not add another level of cache using DRAM!”
Well, the reason we don’t want to add another level of cache is that it can hurt performance unless the cache has a very high hit ratio. In this paper, we performed a deep microbenchmark analysis to understand the behavior of Intel’s implementation of a DRAM cache in Cascade Lake processors.
We found that there are many extra accesses to the DRAM to manage the metadata associated with caches (e.g., checking tags). Because the DRAM and NVRAM share the same command and data busses, these extra metadata accesses directly impact the achievable bandwidth and cause extra latency for demand misses. We define these extra accesses as access amplification.
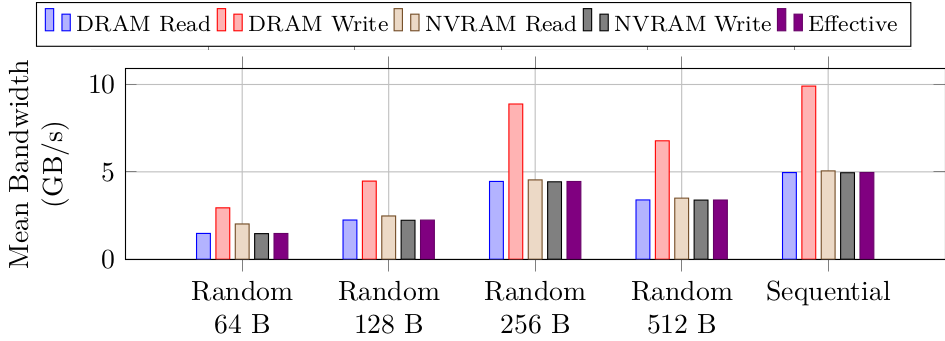
As an example, the graph below shows the measured bandwidth to DRAM for reads and write and NVRAM for reads and writes. It also shows (right-most, dark bar) the effective bandwidth as measured by the program (or the total demand bandwidth of the program). What you can see is that for each demand request, there are five accesses to memories. So, there is an access amplification of 5x. These extra accesses significantly degrade the performance.
Based on similar analysis, we reverse engineered most of the details of the Intel DRAM cache controller. The operations are shown in the flowchart below for LLC Reads (i.e., demand read misses) and LLC Writebacks (i.e., dirty data evicted from the SRAM LLC).

All of this said, if the workload fits in the DRAM cache and the hit rate is high, then you can get a big win from the DRAM cache. However, it’s not clear what workloads would benefit from terabyte-scale RAM and have working sets which fit within ~100 GB.
Performance on real workloads: Beyond microbenchmarks
Our group previously evaluated large-scale convolutional neural networks (CNNs) on NVRAMs in AutoTM. Here, we found that the DRAM cache performed poorly and that managing data movement from software improved the performance greatly. In fact, our prior work on AutoTM led us to dig deeper to understand the DRAM cache implementation (and write this paper!).
Additionally, other groups have developed software-based data movement algorithms for other workloads. For instance, in Sage the authors proposed a change in the graph algorithms to smartly use both DRAM and NVRAM.
Lessons learned, or, how to optimize your algorithm
Through our analysis we developed four key optimizations which AutoTM and Sage use to overcome the limitations of the DRAM cache. Each of these specifically targets at least one of the performance problems with the DRAM cache.
- It is faster to move data in bulk than in 64B chunks.
- Writes perform much better in DRAM than in NVRAM.
- Mixing writes with reads to NVRAM degrades performance non-linearly.
- It is possible to avoid writing data from DRAM to NVRAM if it will never be used again (e.g., temporary data).
These characteristics are unique to DRAM caches with NVRAM devices. Traditional SRAM caches backed by DRAM do not suffer from these performance problems, at least not as much as the DRAM caches.
Next steps
Now that we better understand the problems with the hardware-managed DRAM caches, the next question is what to do about it. One option is the works mentioned above, AutoTM and Sage which take a software-only approach. Another option that we are currently pursuing is how to apply hardware-software co-design to give the benefits of hardware management (namely, transparency to the software) and the benefits of software management (namely, no metadata management in hardware and algorithm-specific optimizations).
See also
We also have a workshop paper and presentation which analyzes running graph workloads on terabyte-scale inputs on NVDIMMs+DRAM caches in more detail.
Acknowledgements
This work in sponsored by Intel.
Citation
Mark Hildebrand, Julian T. Angeles, Jason Lowe-Power and Venkatesh Akella, “A Case Against Hardware Managed DRAM Caches for NVRAM Based Systems,” 2021 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 2021, pp. 194-204, doi: 10.1109/ISPASS51385.2021.00036.
@inproceedings{hildebrand2021dramcache,
author={Mark Hildebrand and Julian T. Angeles and Jason Lowe-Power and Venkatesh Akella},
booktitle={2021 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS)},
title={A Case Against Hardware Managed Caches for Based Systems},
year={2021},
pages={194-204},
doi={10.1109/ISPASS51385.2021.00036}}
Comments